27 Jul

Antes de nada, conviene aclarar que hay mucho abuso—intencionado o accidental—con la terminología. En muchos casos se habla de lo mismo bajo paraguas tan distintos como «inteligencia artificial», «aprendizaje automático» o «machine learning».
En cualquier caso, el origen de este campo se sitúa aproximadamente a mitad del siglo XX, de mano de pioneros como Alan Turing. A lo largo de los ’50, Arthur Samuel presentó uno de los primeros programas capaces de alguna forma de aprendizaje, además de popularizar el término machine learning, y poco después Frank Rosenblatt introdujo las redes neuronales artificiales con su Perceptron1.
Por muchas razones, incluyendo un exceso de optimismo comunicativo, el campo sufrió un relativo estancamiento, que podemos conocer como el primer «invierno» del aprendizaje automático2.
El optimismo regresó con fuerza en la década de los ’80, que vio avances teóricos fundamentales, como el algoritmo de back-propagation. Sin embargo, el impacto de las aplicaciones no estuvo a la altura de las promesas, por lo que el ciclo volvió a un duro invierno. A principios del siglo XXI la situación cambiaría para siempre. En parte aprovechando los avances de hardware como son las unidades de procesamiento GPU, los algoritmos de machine learning comenzaron a asentarse con fuerza en la industria.
Deep learning, reinforcement learning, redes generativas… un diverso grupo de algoritmos nos ha sorprendido con avances que una vez parecieron imposibles. Se dice que inteligencia artificial es todo aquello que la inteligencia artificial aún no ha conseguido realizar. La idea es que, tan pronto como se supera un monumental reto, nuestra comprensión sobre la inteligencia artificial y sobre los retos a los que la aplicamos da un gran salto, y trivializamos los avances pasados.
Así, el ajedrez fue durante décadas el ejemplo paradigmático de una prueba de inteligencia artificial. Es imposible dominar un juego tan complejo a nivel profesional sin hablar de verdadera inteligencia artificial—o eso se decía. Luego llegó la derrota de Kasparov ante Deep Blue en 1996 y nuestra mirada se puso en Go, el siguiente hito inalcanzable—el ajedrez, resulta, no necesitaba «verdarera inteligencia», después de todo. Hasta que AlphaGo venció al maestro Lee Sedol en 2016, como recoge el fantástico documental de igual nombre (AlphaGo, 2017).
Hoy los algoritmos de machine learning están detrás de las acciones más cotidianas de nuestras vidas. Google y demás buscadores, aplicaciones de mapas en nuestros teléfonos, traductores, sistemas de conducción semi- automática o incluso el termostato del salón. Y explican en gran parte de muchas de las mayores fortunas (Apple, Amazon, Google), que han utilizado las nuevas tecnologías para ganar una influencia y riqueza que rivaliza—y supera—a naciones enteras.
Esta breve guía es una introducción a los fundamentos del aprendizaje automático, con un énfasis práctico para que cualquiera pueda usarlo en sus proyectos y negocios, incluyendo cursos y sugerencias de software para hacer más fácil tu comienzo en este apasionante mundo.
¿Qué es el aprendizaje automático?
Aunque ya hemos indicado que los términos se usan de forma indistinta en la práctica, inteligencia artificial y machine learning no son lo mismo.
Inteligencia artificial es un amplísimo campo que se inspira en sistemas inteligentes naturales para mejorar nuestro conocimiento sobre el diseño y funcionamiento de algoritmos y dispositivos. Incluye, por tanto, campos como la robótica e incluso alcanza aplicaciones artísticas.
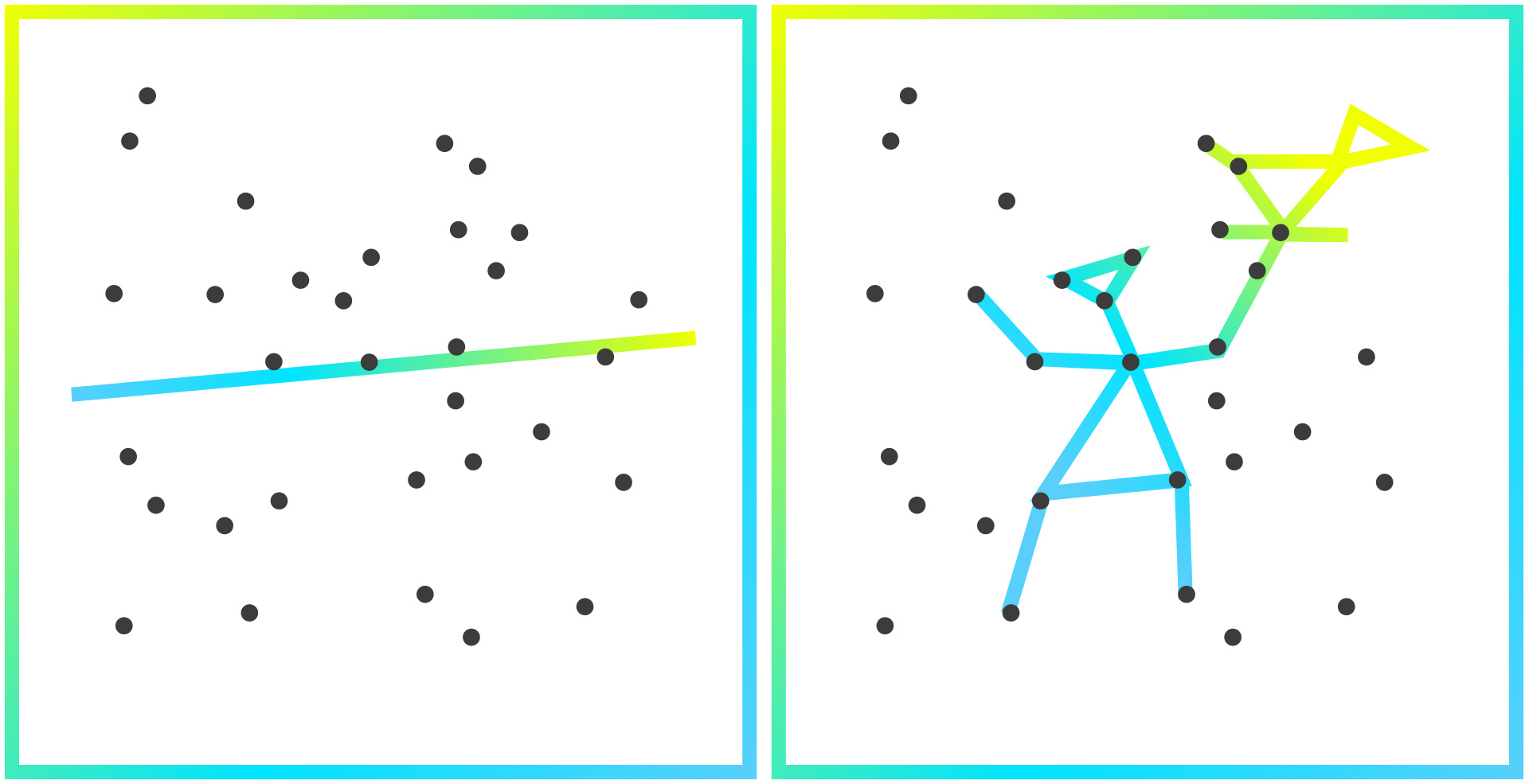
Dentro de la inteligencia artificial encontramos el machine learning, que se centra en la ejecución de tareas sin una guía completa de instrucciones. Los modelos se construyen identificando patrones en los datos, que se utilizan para hacer predicciones. Detrás de descripciones tan rimbombantes encontramos que los ejemplos más básicos son algo muy cercano, como puede ser un ajuste lineal a un conjunto de datos que utilizamos para predecir un valor desconocido: estamos utilizando un patrón para predecir algo no observado.

Por supuesto, machine learning también es un gran campo en sí mismo, e incluye conceptos fundamentales como deep learning, de los que hablaremos más adelante.
¿Cuál es la motivación práctica para todo esto? Incluso las tareas aparentemente más sencillas, como clasificar imágenes de dígitos, resultan abrumadoras para un sistema de reglas.
Tratar de considerar todas las excepciones se vuelve una tarea imposible, lo que se traduce en algoritmos muy complejos, difíciles de mantener y no demasiado efectivos. En lugar de eso, resulta mucho más atractivo utilizar un sencillo algoritmo diseñado para que busque él mismo los patrones que le resulten más útiles en la tarea lo que, en las condiciones correctas, produce asombrosos resultados que superan a humanos expertos.
Machine Learning: Familias y Sabores
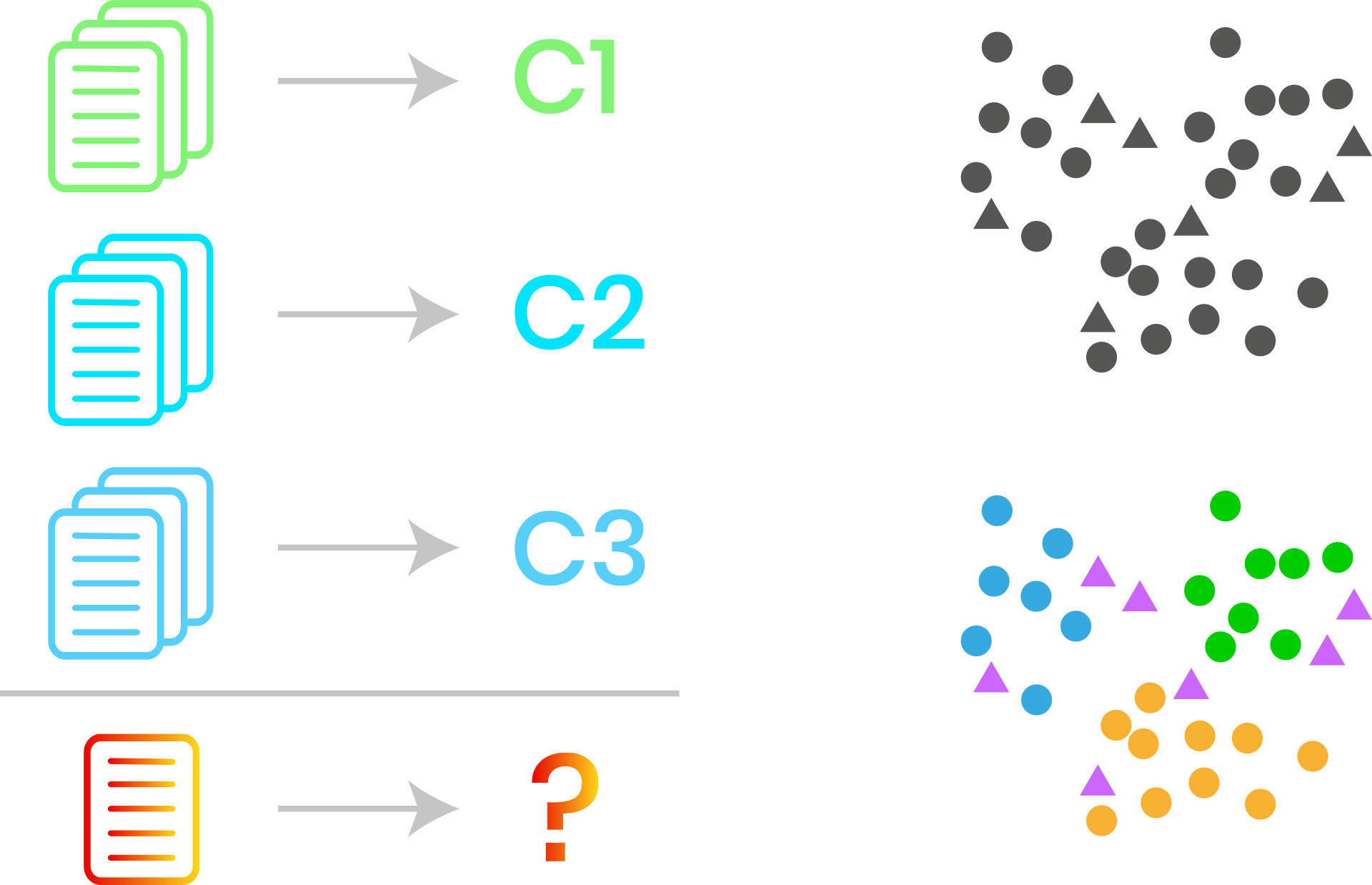
A.- Clasificación
En un problema de clasificación debemos asignar categorías a un ejemplo desconocido. Ya hemos visto un ejemplo sencillo—de explicar—que consiste en distinguir fotografías de perros y gatos. Una aplicación real es identificar imágenes no apropiadas en redes sociales, o clasificar tomates según su estado de maduración.
Por supuesto, no siempre las categorías son únicas y excluyentes. Si imaginamos un clasificador de textos según su temática, es perfectamente posible encontrar un documento que trate de deportes y de medio ambiente simultáneamente.
Los clasificadores son una de las aplicaciones con más potencial empresarial, ya que son tareas repetitivas que consumen gran cantidad de recursos y en las que los algoritmos suelen alcanzar un grado elevado de competencia.

B.- Regresión
No siempre tenemos la suerte de tener datos clasificados por un humano, o incluso donde exista una ground truth, es decir, una única respuesta válida y objetiva a una pregunta. Pero no por ello carecemos de herramientas de trabajo.
Este campo suele incluir técnicas orientadas a la exploración de nuestros datos y la generación de nuevo conocimiento. Sin duda la aplicación más común es clustering, o agrupación, que consiste en agrupar nuestros datos en familias que compartan distintas características.
Los ejemplos más sencillos que suelen verse en guías e introducciones, tienen una respuesta casi insultantemente evidente. Pero eso no debe hacernos subestimar el gran valor de estos algoritmos, que muchas veces son sencillamente imprescindibles para acercarnos siquiera a los dataset más complejos—y más reales.
Si los datos de nuestros clientes contienen 200 campos independientes, puede resultar imposible buscar criterios de agrupación significativos, dejándonos llevar en la práctica por nuestras ideas preconcebidas. Por ello, aplicar técnicas de agrupación a este tipo de datos puede desvelarnos estructuras subyacentes inesperadas en nuestros datos, y de ahí que se hable de generación de conocimiento y exploración.

Aprendizaje semi-supervisado y transferencia de aprendizaje
Cualquier científico de datos se ha enfrentado múltiples veces a problemas muy similares. Por ejemplo, un cliente puede necesitar clasificar documentos según un análisis de sentimiento (positivo, negativo, neutro), mientras que otro cliente necesita clasificación de artículos según temática deportiva, y un tercero necesita clasificar documentos según su tipología (contratos, nóminas, informes). Todos estos encargos son variaciones sobre un mismo tema: ¿tiene sentido repetir todo el trabajo desde cero en cada situación?
Aunque esta pregunta tiene una aplastante lógica comercial, la necesidad surgió antes en el mundo académico. Y la realidad es que no sólo se puede ahorrar tiempo y dinero, sino que es posible conseguir mejores resultados «reciclando» modelos. Y, puestos a reciclar… ¿podemos hacer uso de fuentes de datos externas al problema?
Aprendizaje por transferencia, transferencia de aprendizaje o transfer learning es uno de los avances más significativos en los últimos años en machine learning. Tuvo su origen en las competiciones de computer vision, y la idea es sencilla: imaginemos que nuestro problema es clasificar dos categorías de imagen para las que nuestro dataset es pobre. El procedimiento será primero entrenar un clasificador general utilizando otro dataset diferente, más amplio y conocido. Partiendo de este modelo, adaptamos los parámetros al nuevo problema, pero sin partir de cero. La intuición nos dice que muchos patrones necesarios para clasificar cualquier tipo de imágenes serán comunes (detección de líneas, círculos, gradientes de color).
Esta técnica supuso una revolución en computer vision, y sólo muy recientemente— a partir de 2018—llegó al procesamiento de texto, como comentaremos más adelante. En términos más tangibles, la transferencia de aprendizaje pone en tus manos los modelos más avanzados del mercado, antes sólo al acceso de gigantes tecnológicos.

Redes neuronales y aprendizaje profundo
Existe una gran variedad de familias de algoritmos, como las máquinas de vectores de soporte, los árboles de decisión, modelos bayesianos y un larguísimo etcétera. Entre todas ellas destacan las redes neuronales artificiales y el aprendizaje profundo o deep learning, tan de actualidad y responsables de muchos de los últimos avances.
En realidad, las redes neuronales artificiales son un concepto ya antiguo y sorprendentemente accesible. Una red neuronal no es más que un elemento de software que recibe una lista de valores numéricos sobre los que aplica una sencilla función matemática (típicamente: copiar la suma de lo recibido o devolver cero si el resultado es negativo) y pasa este resultado a otras neuronas con las que se conecta. No es necesaria mayor sofisticación. Como en todos los sistemas complejos, la riqueza surge de la interacción entre múltiples elementos simples.
Como hemos mencionado, estas redes son ya antiguas, pero hubo que esperar hasta el algoritmo de back-propagation y las GPU para que su entrenamiento fuera realmente eficiente.
Típicamente las redes neuronales se organizan en capas, y hablamos de aprendizaje profundo cuando tenemos más de un par de dichas capas de neuronas (un modelo actual puede llegar a cientos de capas).
El procedimiento de entrenamiento es tan simple como intuitivo: se parte de un ejemplo conocido (es decir, dados unos valores numéricos de entrada conocemos los valores numéricos de salida esperados) y se compara, dado el modelo actual, los valores de salida reales con los esperados.
A partir de aquí se realizan pequeños ajustes en los parámetros del modelo para que los valores reales y esperados sean un poco más similares. No vamos a entrar en detalle—abajo tienes mejores fuentes para ello—pero basta decir que el misterio consiste en realizar estos ajustes de forma ordenada, desde el final al principio (de ahí back-propagation) y aplicando derivadas (tarea de la que afortunadamente se encarga el software en nuestro nombre).
Aprendiendo a comunicarse
El lenguaje está en el corazón del pensamiento mismo, por lo que no sorprende que ya filósofos como Descartes o Wittgenstein se dedicaran a reflexionar sobre el lenguaje y la relación entre idiomas. Con la llegada de la computadora, surgió un interés inmediato en crear modelos que permitieran la comunicación entre ordenadores y humanos. Así, por ejemplo, Chomsky realizó trabajos sobre gramáticas que tuvieron gran influencia en el campo.
Pero el campo sufrió el mismo exceso de entusiasmo que tanto daño hizo en machine learning. Por ejemplo, en 1954 investigadores de la universidad de Georgetown predijeron que la traducción automática sería un problema resuelto ¡en cuestión de tres años! Esto se tradujo en una crisis de expectativas y un freno drástico en la inversión.
Durante décadas el campo estuvo dominado por complejos modelos0020«expertos» basados en reglas y gramáticas o, al contrario, por sencillos modelos estadísticos. Tal vez el mejor ejemplo de esto último sea la familia de algoritmos bag of words. La idea clave de estos algoritmos es describir un texto como la colección (desordenada) de las palabras que lo componen, típicamente eliminando las palabras más y menos comunes.
Lógicamente hubo intentos de aplicar al mundo del lenguaje las novedosas técnicas de redes neuronales artificiales y deep learning ya a finales del siglo XX. Pero todas estas técnicas estaban limitadas por un problema fundamental: ¿cómo debe traducirse un texto a lenguaje máquina?
Vectores de palabra
Traducir una fotografía a lenguaje informático es sencillo. Basta con dividir la imagen en pequeñas regiones (píxeles) y traducir la intensidad lumínica (en cada canal de color) por un número. Hacer algo similar con el lenguaje no estan sencillo. En primer lugar, ¿cuál es el píxel del lenguaje? ¿Es cada palabra esa unidad fundamental? ¿O hay que describir el texto letra por letra? Ambas opciones son, en realidad, viables, así como aproximaciones intermedias más habituales en los últimos algoritmos.
La idea más sencilla es codificar el texto utilizando un vocabulario. Contamos las palabras por decenas de miles, y las letras por decenas. Para visualizar esto, pensemos en el ADN, que se puede describir como un texto escrito por cuatro letras (A, C, G, T) que forman palabras (grupos de tres letras). «Vectorizar» estas letras es, por tanto, sencillo. Por ejemplo, en vez de A, podemos escribir (1, 0, 0,0), en vez de C (0, 1, 0, 0), en vez de G (0, 0, 1, 0) y en vez de T (0, 0, 0, 1).
Podríamos hacer lo mismo, pero en este caso traduciendo «palabras» genéticas, que simbolizan aminoácidos (que forman las proteínas). Ya que existen 20 aminoácidos fundamentales, podríamos utilizar un vocabulario de longitud 21 (con un espacio extra para palabras especiales). Así, si nuestro primer aminoácido es alanina, y se escribe GCA, podríamos traducir esa secuencia como (1, 0, 0, …, 0). Y esta idea se puede ampliar hasta vocabularios de decenas de miles de palabras. Las limitaciones de la idea son evidentes. Por un lado, manejar vectores de cuatro elementos es razonable. Trabajar con vectores de 60.000 elementos, un poco menos
Además, supongamos que nuestro vocabulario lo componen las palabras {pera, manzana, balón, barco}. La distancia matemática entre «pera» (1, 0, 0, 0) y «manzana» (0, 1, 0, 0) es la misma que entre «pera» y «barco» (0, 0, 0, 1), ya que estos vectores son iguales en dos posiciones y se diferencian en una unidad en otras dos. No importa el orden.La idea revolucionaria (cuyo germen, una vez más, se encuentra a mediados de siglo XX), consiste en utilizar vectores «densos» para describir una palabra. Así, cada posición de un vector ya no se corresponde a un índice de diccionario. Podemos pensar que cada posición nos describe una cualidad de la palabra.
Por ejemplo, la primera posición podría ser la relación de la palabra con los alimentos, la segunda su «redondez» y la tercera su relación con medios de transporte.
Así, «manzana» podría ser (0.9, 0.7, 0.1). Esto permite que, de forma simultánea, «manzana» sea similar a «pera» (0.9, 0.5, 0.0), aunque también un poco similara «balón» (0.2, 0.9, 0.2) y muy diferente a «barco» (0.0, 0.2, 0.8).
De forma crucial, los vectores de palabra (llamados también word embeddings) nos abren la puerta a reutilizar conocimiento, ya que los vectores que son útiles para vectorizar mis textos pueden ser útiles a otras personas, incluso trabajando sobre distintos corpus documentales. Los word embeddings son uno de los avances fundamentales en la historia del procesamiento de lenguaje natural, y el germen del aprendizaje por transferencia en este campo5 6.
Aprendizaje por transferencia en NLP
Como vimos en la historia del machine learning, aprendizaje por transferencia es un avance clave mediante el que se consigue extrapolar conocimiento entre distintos dataset, lo cual hace posible trabajar con grandes modelos y pocos recursos. El aprendizaje por transferencia nació en el contexto del análisis de imagen, donde resulta casi natural tratar de reutilizar un clasificador de imagen en otro contexto.
En 2018 se produjo un avance fundamental7, que consiguió aplicar los conceptos de transferencia de aprendizaje completa—aplicada a la arquitectura neuronal completa—al campo de NLP. Este trabajo propone entrenar, en primer lugar, un modelo de lenguaje, a partir del cual se completa el modelo de clasificación de texto (o el modelo apropiado para la tarea de texto correspondiente).
Un modelo de lenguaje no es más que un modelo capaz de predecir la palabra correspondiente en un contexto dado. Por ejemplo, esto es lo que utilizan nuestros teléfonos móviles para ayudarnos a predecir la siguiente palabra en un mensaje.
Los avances que ocurrieron a continuación fueron espectaculares. En Foqum seguimos de cerca este excitante y abrumador panorama de avances tecnológicos para poner a tu disposición los últimos avances con las máximas garantías de eficacia, simplicidad y seguridad.
Aplicaciones y Ejemplos
Es una realidad ya irreversible que el machine learning ha llegado para quedarse y, en muchos casos, adaptarse a estas tecnologías es una obligación que determina el futuro de las empresas.
No, los nuevos algoritmos no van a hacer prescindibles a los humanos. Somos más necesarios que nunca. Al tiempo que se automatizan tareas surgen nuevas necesidades y oportunidades. Muchas de las aplicaciones más interesantes de la inteligencia artificial están orientadas a asistirnos en nuestro trabajo, no a reemplazarnos.
Sin embargo, los algoritmos serán sin duda una herramienta fundamental para optimizar los recursos humanos, que actualmente se desperdician en tareas de alto coste y bajo valor como la clasificación de documentos o la extracción de información. Estos algoritmos también nos pueden ayudar a poner datos infrautilizados en valor. Así, la digitalización y procesado inteligente de bases de datos históricas es una oportunidad común.
El rango de aplicaciones del machine learning puede resultar sorprendente y abrumador, y es esencial para entender las empresas más exitosas de la actualidad. Por ejemplo, la visión por computador es esencial en los algoritmos de conducción asistida de Tesla, pero también es clave en cadenas de alimentación (para distinguir, por ejemplo, productos maduros o dañados).
La clasificación de imágenes se ha aplicado a campos tan dispares y exigentes como la astrofísica o la medicina.
Los procesos industriales modernos hacen un uso intensivo de machine learning. Desde la optimización de rutas y recursos a la monitorización inteligente de maquinaria de precisión para realizar mantenimiento predictivo—minimizando costes de reparación y la inactividad en fábrica.
Amazon sería irreconocible sin su servicio de sugerencia de productos de interés, ubicuo en la venta online. Sistemas similares determinan nuestro ocio, por ejemplo, a través de la pre-selección de contenido en Netflix y otros servicios de streaming.
La detección de fraude es una necesidad casi universal en el mundo digital, y una prioridad de primer orden para la banca online e intermediarios de venta. También es universal el deseo de adelantarse a los clientes insatisfechos que acaban abandonando un servicio (churn prediction).
Y todo esto sin hablar de los servicios de búsqueda online, mapas y sistemas de guiado, traductores, asistentes de voz, etc. Nos hayamos dado cuenta o no, vivimos en un mundo tecnológico dominado por algoritmos.
Veamos ahora algunos casos de uso en el contexto del procesamiento de lenguaje natural.
Clasificación de texto: análisis de sentimiento, temática y spam bots
La clasificación de texto es, sin duda, una de las necesidades más habituales de los clientes empresariales en machine learning. Sin embargo, no siempre resulta intuitivo darnos cuenta de qué necesidades encajan en esta categoría.
Un caso común es el análisis de sentimiento y su impacto en la imagen de marca. Análisis de sentimiento no es más que asignar un sentimiento (positivo, negativo y neutro típicamente) a un texto. Por ejemplo, podemos clasificar una serie de tuits en los que se menciona una marca, clasificándolos según estas categorías. Esto puede ser el fundamento de un interesante sistema de monitorización de mercado, donde se identifiquen tendencias y donde se pueda evaluar el impacto de operaciones de marketing e imagen.
La clasificación temática es tan común como variada. Podemos necesitar clasificar artículos periodísticos según sección, o tal vez necesitemos clasificar documentos hospitalarios según distingas categorías clínicas.
Finalmente, los clasificadores de texto pueden ser una herramienta fundamental para apoyarnos en la escalabilidad de nuestros servicios. Por ejemplo, es ya sabido que cualquier comunidad online (ya a través de chats, comentarios, críticas, etc.) va a generar una ingente cantidad de contenido no deseado. Nos enfrentamos a bots de publicidad, así como a trolls que generan increíbles cantidades de contenido tóxico que asfixian a los elementos honestos de la comunidad. Por si esto fuera poco, nos podemos enfrentar incluso a responsabilidades legales si no disponemos de las herramientas de moderación adecuadas.
Un clasificador de texto puede ser una excelente herramienta de primer nivel ante un reto semejante, generando alertas para revisión especializada y tomando medidas preventivas ante los casos más negativos.
Entidades nombradas: palabras clave
Otra de las tareas clásicas en procesamiento de texto es la identificación de entidades. Por ejemplo, podemos estar interesados en localizar todaslas fechas de un documento, así como todos los nombres de empresas o cantidades numéricas.
Esta idea se puede generalizar a nuevos conceptos. Por ejemplo, en el mundo médico podemos crear un algoritmo que identifique todas las menciones a patologías en un documento.
Similitud documental
Cualquier persona con un corpus documental amplio se ha visto en la necesidad de encontrar documentos relacionados con una secuencia de términos, con un párrafo o con otro documento. Esto se conoce como similitud documentaly es una necesidad absoluta en campos como el derecho, donde la búsquedade sentencias relevantes es una tarea constante y crítica.
Reconocimiento óptico de caracteres
Muchos casos de uso reales parten de una necesidad común: la digitalización de documentos físicos. Esto es lo que se conoce como reconocimiento óptico de caracteres, u OCR, por sus siglas en inglés.
La digitalización de documentos es una medida esencial para traducir un coste (almacenamiento de documentos de baja accesibilidad) en un valor.
Resumización y mucho más
La lista completa continúa, encontrando respuesta para todas las necesidades. Por ejemplo, tenemos casos de uso más descriptivos, como la identificación de conceptos clave (otro complemento idóneo para nuestro hipotético sistema de monitorización de mercado). También tenemos usos más en el límite de la tecnología, como pueden ser la resumización de texto, la generación automática de contenido, el parafraseo de texto, etc. Sin duda, un campo apasionante en continuo crecimiento.
Ética y Responsabilidad
Ninguna guía actual sobre machine learning puede estar completa sin unas palabras sobre ética y responsabilidad.
Como hemos visto, los algoritmos definen el mundo moderno, para bien o para mal, y de forma ya irreversible. Como toda tecnología, su impacto puede ser tanto positivo como negativo, por tanto, es nuestra responsabilidad ser conscientes de los riesgos y abusos del machine learning.
Ésta es una conversación importante, que suele desviarse hacia cuestiones sensacionalistas, como la futura revolución de las máquinas (sobre la que han comentado personas de la talla de Stephen Hawkins8) o el dichoso trolley (ya sabes, ese famoso coche que puede elegir entre matar un perro superdotado o girar o acabar con la vida de una viejecita de 102 años).
En realidad, deberíamos estar hablando de cuestiones como privacidad9, representación y transparencia. Por ejemplo, son notables los abusos que se han producido con tecnologías de reconocimiento facial. Desde su abuso por la policía en EEUU (donde, por ejemplo, utilizaron imágenes de famosos como sustituto a descripciones de sospechosos10) a represión racial en China.11
También debemos estar alerta frente al oportunismo y las pseudociencias. Aquí se pueden enmarcar muchas iniciativas más o menos bienintencionadas para atajar la pandemia de Covid-19, o algoritmos de que prometen resolver la selección de personal mediante el análisis de breves fragmentos de vídeo12. No hace falta decir que esta es una promesa imposible y que acaba discriminando a los grupos habituales.
Un aspecto que el usuario de algoritmos debe tener en cuenta es el hecho de que los algoritmos reproducen los sesgos de los datos que le ofrezcamos. Que nuestro algoritmo no tenga sesgos, y que nosotros tampoco los tengamos no sirve de nada si los sesgos se infiltran en nuestros datos, algo más difícil de evitar de lo que parece.
Un ejemplo ya famoso es el servicio de reconocimiento de imagen de Amazon, con métricas formidables para hombres blancos… y desastrosas cuando se aplica a mujeres negras13. Sin duda, un reflejo de un dataset de entrenamiento mal construido— como vemos, un resultado racista no implica necesariamente una motivación racista, por lo que todos debemos estar en guardia ante este problema.
1Rosenblatt, Frank (1957). “The Perceptron—a perceiving and recognizing automaton”. Report 85-460-1. Cornell Aeronautical Laboratory.
2https://en.wikipedia.org/wiki/AI_winter
3https://deepmind.com/research/publications/playing-atari-deep-reinforcement- earning
4https://eng.uber.com/go-explore/
5https://www.tensorflow.org/tutorials/text/word_embeddings
6https://ruder.io/word-embeddings-1/
7https://nlp.fast.ai/classification/2018/05/15/introducing-ulmfit.html
8https://www.bbc.com/news/technology-30290540
9https://bit.ly/32syob6
10https://www.nbcnews.com/news/us-news/nypd-used-celebrity-doppelg-ngers-fudge-facial-recognition-results-researchers-n1006411
11https://bit.ly/32yRRqD
12https://wapo.st/2Q7a9fR
13https://www.bbc.com/news/technology-47117299
Artículos relacionados





Email: info@foqum.io
Teléfono: +34 675 481 701

C. de Agustín Durán, 24, Local bajo izquierda, 28028 Madrid.